Partition Clustering
Partition clustering is a popular technique in machine learning used to divide a dataset into distinct clusters based on the similarity of the data-points. In partitioned clustering, each data point belongs to a single cluster, and the goal is to group the data points such that the similarity within each cluster is high, and the similarity between different clusters is low. In this way, partitioned clustering helps to identify natural groupings within the dataset and provides insights into the underlying structure of the data.
One of the most widely used partitioned clustering algorithms is k-means clustering. K-means clustering is an unsupervised learning algorithm that iteratively partitions the dataset into k clusters, where k is the number of clusters specified by the user. The algorithm begins by randomly selecting k data points as initial cluster centroids. Each data point is then assigned to the nearest centroid based on its distance from the centroid. The algorithm then updates the centroids based on the mean of the data points assigned to each cluster. This process is repeated until the centroids no longer change, or a maximum number of iterations is reached.
Example
To understand partition clustering with an example, consider the following example:
Let's say we have a dataset of points in a two-dimensional space:
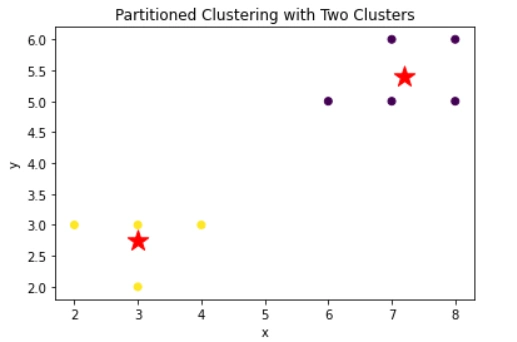
{(2,3), (3,2), (3,3), (4,3), (6,5), (7,5), (8,5), (7,6), (8,6)}
We want to group these points into k clusters using the k-means algorithm. Let's say we choose k=2.
Firstly, the cluster centers are randomly initialized. Let the two cluster centers are:
1) Cluster 1 center: (3,3)
2) Cluster 2 center: (6,5)
Assign each point to the closest cluster center:
- (2,3) -> Cluster 1
- (3,2) -> Cluster 1
- (3,3) -> Cluster 1
- (4,3) -> Cluster 1
- (6,5) -> Cluster 2
- (7,5) -> Cluster 2
- (8,5) -> Cluster 2
- (7,6) -> Cluster 2
- (8,6) -> Cluster 2
3) Update the cluster centers to be the mean of the points assigned to them:
Cluster 1 center: (3,2.75)
Cluster 2 center: (7,5.8)
Repeat steps 2-3 until convergence (when the cluster assignments no longer change):
Iteration 2:
- (2,3) -> Cluster 1
- (3,2) -> Cluster 1
- (3,3) -> Cluster 1
- (4,3) -> Cluster 1
- (6,5) -> Cluster 2
- (7,5) -> Cluster 2
- (8,5) -> Cluster 2
- (7,6) -> Cluster 2
- (8,6) -> Cluster 2
Cluster 2 center: (7,5.8)
Since the cluster assignments did not change from iteration 1 to iteration 2, we have converged to a stable clustering. The final clusters are:
Cluster 1: {(2,3), (3,2), (3,3), (4,3)}
Cluster 2: {(6,5), (7,5), (8,5), (7,6), (8,6)}
Advantages of Partitioned clustering:
- Scalability: Partitioned clustering is highly scalable, which means it can handle large datasets with many data objects. This is because the algorithm does not require the entire dataset to be loaded into memory at once. Instead, it works by processing data objects one at a time or in small batches, making it suitable for handling big data problems.
- Efficiency: Partitioned clustering algorithms are efficient in terms of computational resources and processing time. The most popular partitioned clustering algorithm is k-means, which is computationally efficient and can converge to a solution quickly. This makes it an attractive option for real-time applications and large-scale data processing.
- Interpretability: Partitioned clustering algorithms are easy to interpret, making it easier for non-experts to understand the results. Clustering results can be visualized using graphs and charts, which can help identify patterns and trends in the data. This makes partitioned clustering a useful tool for data exploration and hypothesis generation.
- Flexibility: Partitioned clustering algorithms can be used with a wide range of data types, including numerical, categorical, and binary data. This makes it a versatile tool for data analysis and can be applied to a variety of real-world problems in different industries.
- Performance: Partitioned clustering algorithms can achieve high performance in terms of clustering quality. The clustering results can be evaluated using various metrics such as silhouette score, purity, and F1 score. These metrics provide a quantitative measure of the clustering quality, which can help select the best clustering algorithm and parameter settings.
- Scalability:Partitioned clustering can handle datasets that are too large to fit into memory. Partitioned clustering algorithms process data objects one at a time or in small batches, which makes them scalable for big data problems.
- Efficiency:Partitioned clustering algorithms are computationally efficient and can converge to a solution quickly. The most popular partitioned clustering algorithm is k-means, which is known for its efficiency.
- Interpretability: Partitioned clustering algorithms are easy to interpret, making it easier for non-experts to understand the results. Clustering results can be visualized using graphs and charts, which can help identify patterns and trends in the data. This makes partitioned clustering a useful tool for data exploration and hypothesis generation.
- Flexibility: Partitioned clustering algorithms can be used with a wide range of data types, including numerical, categorical, and binary data. This makes it a versatile tool for data analysis and can be applied to a variety of real-world problems in different industries.
- Performance: Partitioned clustering algorithms can achieve high performance in terms of clustering quality. The clustering results can be evaluated using various metrics such as silhouette score, purity, and F1 score. These metrics provide a quantitative measure of the clustering quality, which can help select the best clustering algorithm and parameter settings.
Disadvantages of Partitioned clustering:
- Sensitivity to initial conditions: Partitioned clustering algorithms are sensitive to the initial conditions of the algorithm, which means that different initial starting points can result in different clustering results. This sensitivity can result in suboptimal clustering solutions, which can affect the quality of the clustering.
- Difficulty in determining the number of clusters: Partitioned clustering algorithms require the user to specify the number of clusters in advance. However, determining the optimal number of clusters is not always straightforward and can require trial and error or the use of heuristic methods. This difficulty in determining the number of clusters can result in suboptimal clustering results.
- Limited to spherical or elliptical clusters: Partitioned clustering algorithms are limited to identifying spherical or elliptical clusters. This means that they may not be effective in identifying clusters that have more complex shapes, such as clusters that are elongated or irregular.
- Inability to handle noise and outliers: Partitioned clustering algorithms are sensitive to noise and outliers in the data. These data points can influence the clustering results and can result in suboptimal clusters. It can be challenging to identify and remove these outliers, which can affect the quality of the clustering.
- Lack of robustness: Partitioned clustering algorithms are not very robust to changes in the data. A small change in the data can result in a completely different clustering solution. This lack of robustness can make partitioned clustering less reliable in real-world applications.
- Bias towards balanced clusters:Partitioned clustering algorithms tend to bias towards clusters that have similar sizes. This means that clusters that are significantly larger or smaller than other clusters may not be identified correctly. This bias towards balanced clusters can be problematic in some applications where identifying small or large clusters is important.
- Can be computationally expensive: Some partitioned clustering algorithms can be computationally expensive, especially for large datasets. This can result in longer processing times, making it less suitable for real-time applications.
Advertisement
Advertisement