Clustering
Clustering is a type of unsupervised machine learning technique where a set of objects or data points are grouped into clusters based on their similarities. In other words, it is a technique to identify similarities and differences between different data points and group them accordingly. The primary goal of clustering is to identify patterns in data and to create meaningful subgroups within a dataset.
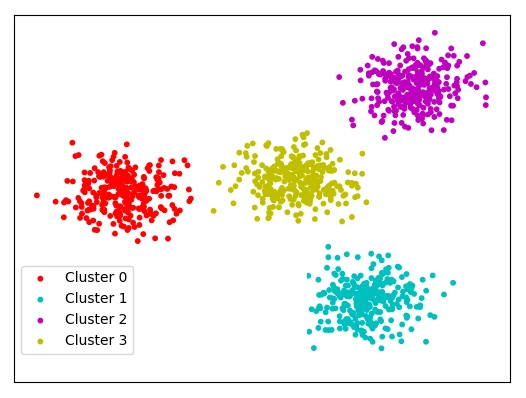
In clustering, the machine learning algorithm automatically identifies patterns in the data, which means there is no need for the algorithm to be trained on labeled data. This makes clustering a powerful tool for exploratory data analysis, as well as for identifying anomalies and outliers. Clustering is widely used in various applications such as customer segmentation, image segmentation, pattern recognition, and anomaly detection.
Clustering can be Hard Clustering or Soft Clustering
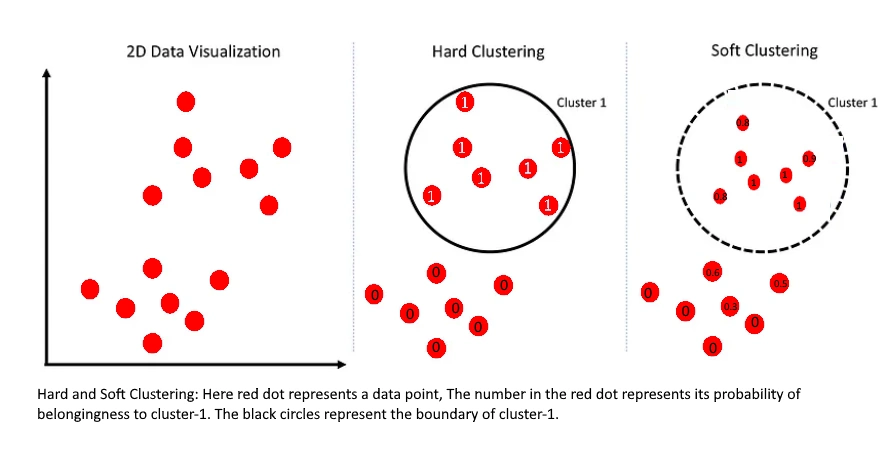
Hard Clustering
Hard clustering is a clustering method in which each data point is assigned to a single cluster. This means that every point in the dataset is grouped together with other points that are most similar to it, based on a given similarity metric or distance measure.
In hard clustering, the number of clusters is typically pre-determined by the user, and each data point is assigned to only one of those clusters. The assignment is based on the minimum distance between the point and the cluster centers, or by maximizing a similarity score between the point and the cluster.
Some common examples of hard clustering algorithms are K-means, hierarchical clustering, and DBSCAN (with a fixed epsilon and minimum points). These methods are widely used in various fields such as machine learning, data mining, image processing, and natural language processing.
Soft Clustering
Soft clustering, also known as fuzzy clustering, is a clustering method in which each data point can belong to multiple clusters with varying degrees of membership. This means that each data point is assigned a membership value or probability for each cluster, indicating the degree to which it belongs to that cluster.
Unlike hard clustering, in which a point can only belong to one cluster, soft clustering allows for overlapping or ambiguous membership. This is useful when data points do not have a clear-cut boundary between clusters or when a point can have characteristics of multiple clusters.
Soft clustering algorithms typically use probabilistic models or fuzzy logic to assign membership values to each data point. Some common examples of soft clustering algorithms are Fuzzy C-means (FCM), Possibilistic C-means (PCM), and Gaussian mixture models (GMM).
Soft clustering is often used in fields such as pattern recognition, image processing, and bioinformatics, where data may have ambiguous or overlapping characteristics, and it can provide more nuanced and flexible clustering solutions compared to hard clustering.
Types of Clustering:
Clustering can be broadly classified into two types based on the way clusters are formed:
- Hierarchical Clustering: Hierarchical clustering is a type of clustering where the data points are grouped based on their similarities in a hierarchical manner. The hierarchical clustering technique can be further classified into two types:
- Agglomerative Hierarchical Clustering: Agglomerative Hierarchical clustering is a bottom-up approach, where each data point initially forms a single cluster, and clusters are merged iteratively based on their similarity until all the data points are in a single cluster. The algorithm starts by treating each data point as a single cluster and then iteratively merging the closest pair of clusters until all data points are in one cluster.
- Divisive Hierarchical Clustering:Divisive hierarchical clustering is a top-down approach, where all the data points initially form a single cluster, and then clusters are divided iteratively based on their dissimilarity until each data point is in a separate cluster. The algorithm starts by treating all data points as a single cluster and then iteratively dividing the largest cluster into two until each data point is in a separate cluster.
- Partitional Clustering:Partitional clustering is a type of clustering where the data points are grouped into a fixed number of clusters. The partitional clustering technique can be further classified into two types:
- K-Means Clustering:K-Means clustering is a partitional clustering technique that groups the data points into k number of clusters. The algorithm starts by randomly selecting k centroids, and then each data point is assigned to the nearest centroid. After that, the centroids are recalculated based on the mean of the data points in each cluster, and the process is repeated until the centroids no longer change.
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN):DBSCAN is a partitional clustering technique that groups the data points into clusters based on their density. The algorithm starts by selecting a random data point, and then it forms a cluster by adding nearby data points within a predefined distance. The algorithm continues to add data points to the cluster until it reaches a point where there are no more nearby data points. Then, it starts the process with a new unvisited data point.
Applications of Clustering:
- Image segmentation: Clustering algorithms can be used to group similar pixels in an image, making it possible to identify objects and separate them from the background.
- Customer segmentation: Clustering can help businesses to identify different groups of customers based on their purchasing habits, demographics, and other characteristics. This can be useful in developing targeted marketing strategies.
- Anomaly detection: Clustering algorithms can be used to identify data points that are significantly different from the rest of the data. This can be useful in detecting anomalies or outliers in datasets.
- Recommender systems: Clustering can help to group similar items or users together, which can be used to make personalized recommendations based on a user's preferences.
- Document clustering: Clustering can help to group similar documents together, which can be useful in organizing large collections of documents and making it easier to search for specific information.
- Bioinformatics: Clustering is widely used in bioinformatics to group genes or proteins based on their function or similarity.
- Fraud detection: Clustering algorithms can be used to detect fraudulent activity by grouping similar transactions together and identifying anomalies.
Advertisement
Advertisement