Random Forest
Random Forest is a powerful machine learning algorithm that is used for both classification and regression tasks. It is a type of ensemble learning method that builds multiple decision trees and combines their outputs to make predictions. The algorithm is based on the concept of decision trees and Bagging
A decision tree is a tree-like model that is used to make decisions based on multiple conditions. It consists of nodes and edges, where each node represents a decision, and each edge represents a condition. The topmost node is called the root node, and the bottommost nodes are called leaf nodes. To make a prediction, we traverse the tree from the root node to a leaf node, based on the conditions present at each node.
In random forest, multiple decision trees are built, each using a random subset of the training data and a random subset of the features. This random selection ensures that each tree is different from the other trees, reducing the chance of overfitting and improving the generalization performance of the model.
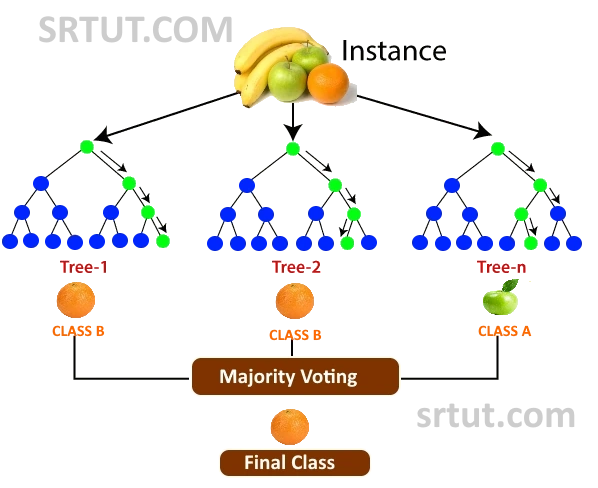
The output of each tree in random forest is combined to make a final prediction. For classification tasks, the majority vote of the classes predicted by all the trees is taken as the final prediction. For regression tasks, the average of the predicted values of all the trees is taken as the final prediction.
The hyperparameters of random forest include the number of trees, the maximum depth of the tree, and the number of features used to split each node. The number of trees is usually set high enough to ensure that the model is not underfitting or overfitting the data. The maximum depth of the tree is set to prevent overfitting, while the number of features used to split each node is set to balance between bias and variance.
Random Forest has many advantages over other machine learning algorithms. It can handle both categorical and numerical data, is resistant to outliers and missing values, and can be used for both classification and regression tasks. It also provides feature importance scores, which can be used to identify the most important features in the dataset.
Random Forest is widely used in many applications, including credit risk analysis, fraud detection, stock price prediction, and medical diagnosis. However, it may not be suitable for datasets with a high number of features or high-dimensional data due to the curse of dimensionality.
Ensemble Learning & Bagging
Ensemble learning is a machine learning technique that involves combining multiple models to improve the overall performance of a prediction or classification task. Ensemble learning aims to achieve better results by using multiple models to make predictions, rather than relying on a single model.
There are two main approaches to ensemble learning:
- Bagging (Bootstrap Aggregation): Bagging involves training multiple models independently on different subsets of the training data, where each model is trained on a random subset of the data. The predictions of all models are combined to produce the final prediction. Bagging reduces overfitting by reducing the variance in the models.
- Boosting: Boosting involves training multiple models sequentially, where each model is trained on a modified version of the data that emphasizes the misclassified examples in the previous model. Boosting reduces bias in the models by increasing the accuracy of the predictions.
nsemble learning can be applied to different types of machine learning algorithms, such as decision trees, neural networks, and support vector machines. Ensemble learning is particularly useful in situations where the performance of a single model is limited, such as when dealing with noisy or incomplete data, or when the model is prone to overfitting. By combining the predictions of multiple models, ensemble learning can improve the accuracy, robustness, and generalization of the prediction or classification task.
Advantages of Random Forest Algorithm:
Some of the most critical advantages of using Random Forest Algorithm are:
- Robustness: Random Forests are robust to noise and outliers in the data, making them a good choice for datasets with missing or noisy data.
- Accuracy: Random Forests often provide high accuracy and robust performance, particularly when compared to other machine learning algorithms.
- Feature Importance: Random Forests can provide information about the relative importance of different features, helping to identify the most important factors that contribute to a particular outcome.
- Non-parametric: Random Forests are non-parametric, meaning they can capture complex non-linear relationships between features and the target variable without making assumptions about the underlying distribution of the data.
- Ensemble Approach: Random Forests use an ensemble approach, combining the predictions of multiple decision trees to produce a more accurate and reliable result.
- Scalability: Random Forests are relatively scalable and can handle large datasets with many features.
- Low Risk of Overfitting: Random Forests can help prevent overfitting, as they average the results of multiple decision trees, reducing the risk of relying on any single decision tree that may have overfit the data.
- Versatility: Random Forests can be used for both classification and regression tasks, making them a versatile tool for a range of machine learning applications.
Disadvantages of Random Forest Algorithm
While Random Forest is a powerful and widely used machine learning algorithm, it has some limitations also
- Interpretability: The output of Random Forests can be difficult to interpret, as the algorithm combines many decision trees. It may not be straightforward to determine which features are the most important or how each decision contributes to the final prediction.
- Overfitting: Random Forests are prone to overfitting if the model is too complex or if there is not enough data to support it. Overfitting can result in high accuracy on the training data but poor performance on new, unseen data.
- Computationally Expensive: Random Forests require a significant amount of computational power to train, especially when dealing with large datasets. This can make it difficult to implement on certain hardware or in real-time scenarios.
- Biased Towards Features with Many Levels: Random Forests tend to be biased towards features with many levels or categories, which can lead to over-representation of certain features in the model and poorer performance on other features.
- Imbalanced Datasets: Random Forests can have difficulty handling imbalanced datasets, where one class is significantly more prevalent than the others. This can lead to poor performance on the minority class and bias towards the majority class.
- Lack of Extrapolation: Random Forests may not be able to extrapolate beyond the range of the training data, which can limit their usefulness in predicting new or novel data points that fall outside the range of the training data.
Advertisement
Advertisement