Partition Clustering Code Implementation
In this code random data points as discussed in partition clustering theory part. You can copy the code and execute it in juypter or PyCharm.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Define the data points
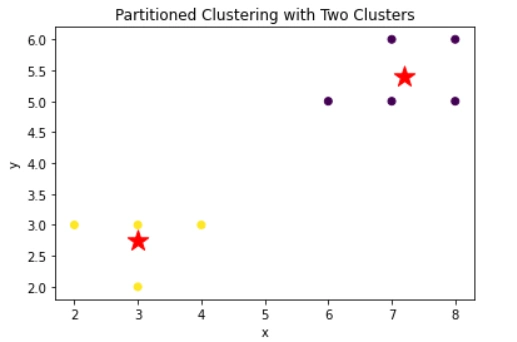
X = np.array([[2, 3], [3, 2], [3, 3], [4, 3], [6, 5], [7, 5], [8, 5], [7, 6], [8, 6]])
# Define the number of clusters
k = 2
# Run the KMeans algorithm
kmeans = KMeans(n_clusters=k, random_state=0).fit(X)
# Get the cluster labels and centroids
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# Plot the scatter plot with the points and their assigned clusters
plt.scatter(X[:,0], X[:,1], c=labels)
plt.scatter(centroids[:,0], centroids[:,1], marker='*', s=300, c='red')
plt.title('Partitioned Clustering with Two Clusters')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
The output of the above code:
Advertisement
Advertisement